Spark Streaming with Kafka-Connect Debezium Connector
A quick guide to set up Debezium and use Spark-Streaming Job as a Kafka consumer.
Bird’s eye view of the architecture:
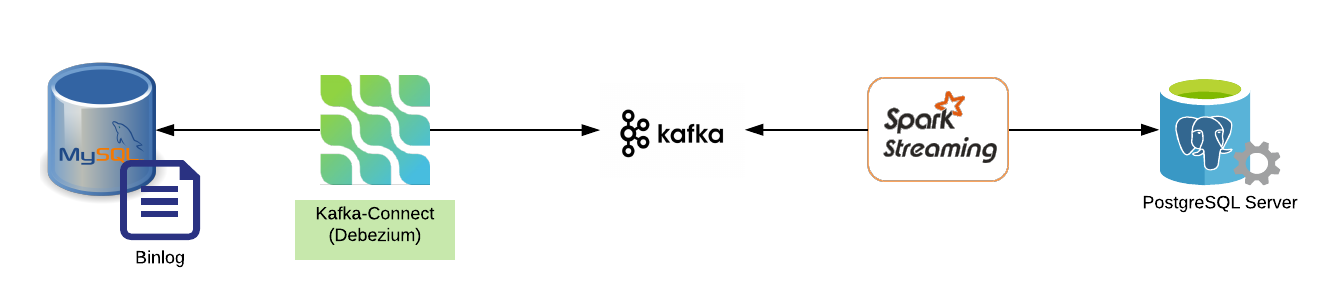
Debezium
Debezium is an open-source distributed platform for change data capture. It provides a set of Kafka connector which are capable of reading from the Database Binlog files and produce the changes as events in Kafka.
As a CDC, it gives you a state of Database Row before & after the commit and also tells what kind of operation it was i.e Create/ Update or Delete.
A Debezium Kafka message looks like:
{
"schema":{
"type":"struct",
"fields":[
{
"type":"struct",
"fields":[
{
"type":"int32",
"optional":false,
"field":"order_number"
},
{
"type":"int32",
"optional":false,
"name":"io.debezium.time.Date",
"version":1,
"field":"order_date"
},
{
"type":"int32",
"optional":false,
"field":"purchaser"
},
{
"type":"int32",
"optional":false,
"field":"quantity"
},
{
"type":"int32",
"optional":false,
"field":"product_id"
}
],
"optional":true,
"name":"dbserver1.inventory.orders.Value",
"field":"before"
},
{
"type":"struct",
"fields":[
{
"type":"int32",
"optional":false,
"field":"order_number"
},
{
"type":"int32",
"optional":false,
"name":"io.debezium.time.Date",
"version":1,
"field":"order_date"
},
{
"type":"int32",
"optional":false,
"field":"purchaser"
},
{
"type":"int32",
"optional":false,
"field":"quantity"
},
{
"type":"int32",
"optional":false,
"field":"product_id"
}
],
"optional":true,
"name":"dbserver1.inventory.orders.Value",
"field":"after"
},
{
"type":"struct",
"fields":[
{
"type":"string",
"optional":false,
"field":"version"
},
{
"type":"string",
"optional":false,
"field":"connector"
},
{
"type":"string",
"optional":false,
"field":"name"
},
{
"type":"int64",
"optional":false,
"field":"ts_ms"
},
{
"type":"string",
"optional":true,
"name":"io.debezium.data.Enum",
"version":1,
"parameters":{
"allowed":"true,last,false"
},
"default":"false",
"field":"snapshot"
},
{
"type":"string",
"optional":false,
"field":"db"
},
{
"type":"string",
"optional":true,
"field":"table"
},
{
"type":"int64",
"optional":false,
"field":"server_id"
},
{
"type":"string",
"optional":true,
"field":"gtid"
},
{
"type":"string",
"optional":false,
"field":"file"
},
{
"type":"int64",
"optional":false,
"field":"pos"
},
{
"type":"int32",
"optional":false,
"field":"row"
},
{
"type":"int64",
"optional":true,
"field":"thread"
},
{
"type":"string",
"optional":true,
"field":"query"
}
],
"optional":false,
"name":"io.debezium.connector.mysql.Source",
"field":"source"
},
{
"type":"string",
"optional":false,
"field":"op"
},
{
"type":"int64",
"optional":true,
"field":"ts_ms"
}
],
"optional":false,
"name":"dbserver1.inventory.orders.Envelope"
},
"payload":{
"before":{
"order_number":10004,
"order_date":16852,
"purchaser":1003,
"quantity":1,
"product_id":107
},
"after":{
"order_number":10004,
"order_date":16852,
"purchaser":1003,
"quantity":3,
"product_id":107
},
"source":{
"version":"1.0.3.Final",
"connector":"mysql",
"name":"dbserver1",
"ts_ms":1589660547000,
"snapshot":"false",
"db":"inventory",
"table":"orders",
"server_id":223344,
"gtid":null,
"file":"mysql-bin.000003",
"pos":354,
"row":0,
"thread":12,
"query":null
},
"op":"u",
"ts_ms":1589660547884
}
}Spark Streaming
We are using Spark-Streaming as a processing engine, it reads the Debezium events from the Kafka topic and pushes the changes to PostgreSQL.
Sample Code
The sample code under discussion can be cloned from Github
How to bring the infrastructure up and running
docker-compose
version: '3.0'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
container_name: zookeeper
ports:
- 2181:2181
- 2888:2888
- 3888:3888
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
- ZOOKEEPER_CLIENT_PORT=2181
- ZOOKEEPER_TICK_TIME=2000
kafka:
image: confluentinc/cp-kafka:latest
container_name: kafka
ports:
- 9092:9092
- 29092:29092
depends_on:
- zookeeper
environment:
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
- KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT
- KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1
mysql:
image: debezium/example-mysql:1.0
container_name: mysql
ports:
- 3306:3306
environment:
- MYSQL_ROOT_PASSWORD=debezium
- MYSQL_USER=mysqluser
- MYSQL_PASSWORD=mysqlpw
connect:
image: debezium/connect:1.0
container_name: connect
ports:
- 8083:8083
depends_on:
- kafka
- mysql
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=1
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
postgresql:
image: sameersbn/postgresql:9.4
container_name: postgresql
environment:
- DEBUG=false
- DB_USER=test
- DB_PASS=Test123
- DB_NAME=test
ports:
- "5432:5432"Execute:
docker-compose up -dIt will bring up the following containers:

Add Debezium-Connector
Once the container “connect” is up and running, execute the following command to add MySqlConnector:
curl -X POST \
http://localhost:8083/connectors/ \
-H 'Cache-Control: no-cache' \
-H 'Content-Type: application/json' \
-d '{
"name": "inventory-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "1",
"database.server.name": "dbserver1",
"database.whitelist": "inventory",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "schema-changes.inventory",
"decimal.handling.mode": "double",
"snapshot.mode": "when_needed",
"table.whitelist":"inventory.orders"
}
}'The connector is now ready to read MySQL Binlog files.
MySQL Database
The MySQL database in the docker-compose comes with a sample database and has the required database changes which are required for the connector to read the DB logs.

If you plan to use your own database then ensure the following things:
- The MySQL config for ‘binlog_format’ should be ROW
show variable 'binlog_format'; //should be ROW2. Binary logging should be enabled. In MySQL cnf file:
# Uncomment the following if you want to log updates
log-bin=mysql-bin
expire_logs_days = 10
binlog_format = rowKafka Topic
Once the connector is added via curl command, it starts pushing the snapshot changes to Kafka, and once that is done it changes it’s mode to Binlog where it is watching the changes in Binlog file and pushed them to Kafka.
Kafka Topic:
kafkacat -b localhost:29092 -t dbserver1.inventory.orders
Spark Streaming Job
The Spark-Streaming will listen to the Kafka Message, serialize/deserialize the message and push the change to PostgreSQL.
package com.sg.job.streaming
import com.sg.wrapper.SparkSessionWrapper
import org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object StreamingJob extends App with SparkSessionWrapper {
val currentDirectory = new java.io.File(".").getCanonicalPath
val kafkaReaderConfig = KafkaReaderConfig("localhost:29092", "dbserver1.inventory.orders")
val jdbCConfig = JDBCConfig(url = "jdbc:postgresql://localhost:5432/test")
new StreamingJobExecutor(spark, kafkaReaderConfig, currentDirectory + "/checkpoint/job", jdbCConfig).execute()
}
case class JDBCConfig(url: String, user: String = "test", password: String = "Test123", tableName: String = "orders_it")
case class KafkaReaderConfig(kafkaBootstrapServers: String, topics: String, startingOffsets: String = "latest")
case class StreamingJobConfig(checkpointLocation: String, kafkaReaderConfig: KafkaReaderConfig)
class StreamingJobExecutor(spark: SparkSession, kafkaReaderConfig: KafkaReaderConfig, checkpointLocation: String, jdbcConfig: JDBCConfig) {
def execute(): Unit = {
// read data from kafka and parse them
val transformDF = read()
.selectExpr("CAST(key AS STRING) as key", "CAST(value AS STRING) as value", "topic")
transformDF
.writeStream
.option("checkpointLocation", checkpointLocation)
.foreachBatch { (batchDF: DataFrame, _: Long) => {
batchDF.write
.format("jdbc")
.option("url", jdbcConfig.url)
.option("user", jdbcConfig.user)
.option("password", jdbcConfig.password)
.option("driver", "org.postgresql.Driver")
.option(JDBCOptions.JDBC_TABLE_NAME, jdbcConfig.tableName)
.option("stringtype", "unspecified")
.mode(SaveMode.Append)
.save()
}
}.start()
.awaitTermination()
}
def read(): DataFrame = {
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", kafkaReaderConfig.kafkaBootstrapServers)
.option("subscribe", kafkaReaderConfig.topics)
.option("startingOffsets", kafkaReaderConfig.startingOffsets)
.load()
}
}PostgreSQL
Once the job is running, you can connect to PostgreSQL DB and see a table with the name orders_it has been created.

Now, play around with MySQL DB and see the changes getting pushed to PostgreSQL.
The same can be simulated via an Integration Test.
